Model Structures
CART models
CART model is used in the last step of GMM-pipeline. It has stable behavior, but the generation of CART depends on a given alignment of GMM-system.
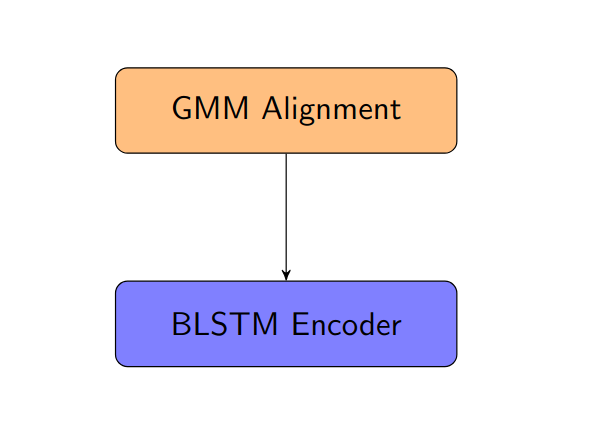
CART model trained with GMM-alignment
BLSTM encoder consists of 6 BLSTM layers with the size of 512, dropout rate 0.1, "L2" normalization. It is applied to all the models in this chapter. The output of BLSTM encoder is directly aligned to The GMM-alignment.
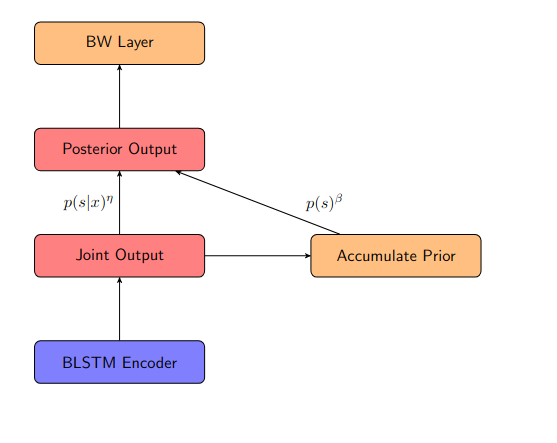
CART model trained with soft alignment
The BLSTM Encoder keeps the same. "Joint Output" is a copy of encoder output, which stands for the joint probability of all states . "Accumulate Proir" represents a layer that accumulates the probability of "Joint Outuput", . The prior probability is saved in a variable , which updates during training with the factor : .
Factored diphone models
The following models substitute the state-tying CART with factored layers. Encoder output are forwarded to two independent MLPs, which represent respectively the probability of left context and probability of center and state given different left context .
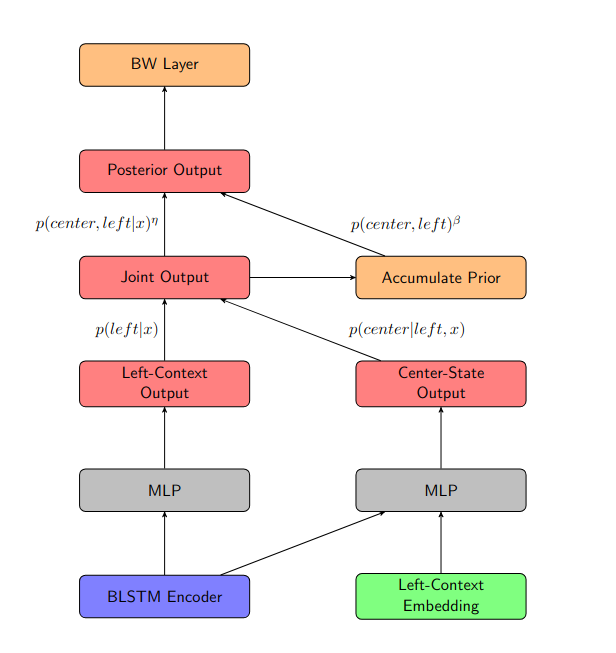
Factored diphone joint output BW
To get the joint output the two layers Left-Context Output and Center-State Output are combined, which corresponds to the formulation .
Factored diphone joint output Viterbi
It has the same factored part as the model above, aligned with GMM-alignment.

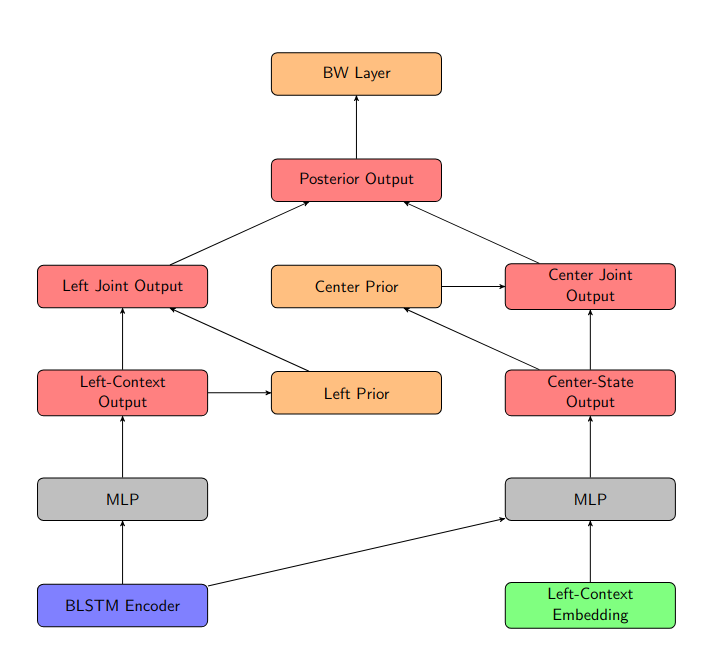
Factored diphone model with separate outputs and BW-alignment
In contrast to the model with joint output and BW-alignment, this model is finer that the Left Output and Center Output have their own prior, which can also be scaled independently.
Factored diphone separate output Viterbi
In this model there is not a joint probability. The GMM-alignment is factored into Left Alignment and Center Alignment, aligning with Left-Context Output and Center-State Output respectively.
